
Convert data into tensors - End to End Machine Learning Course 11
Convert data into tensors - End to End Machine Learning Course 11
Both structured and unstructured data may need help converting to numbers. Structured data include texts, strings. Unstructured data can be documents, files. Machine learning models consume numeric data as input, and specifically the data is efficiently loaded as Tensors, parallel processed if applicable, and Tensor objects usually come with auto gradient capabilities. Tensor is a data structure that modern deep learning libraries use. Each may be implemented or used a bit differently. It is usually a multi-dimensional matrix with functionalities that is beyond math and is useful for deep learning compute and data engineering such as auto gradient compute. Updated August 2020.
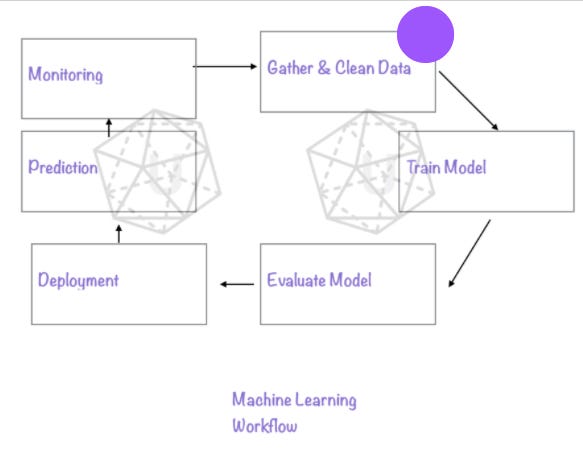
Where does this course fit in the machine learning workflow? The purple dot indicate the position. In addition Gather & Clean Data, we also want to encode or convert data in this step.
Encoding is a large field and with much complexity (It can be used to make information more compact, encode parameters into URI URL etc.). Right now we are just focusing on converting frequently seen data types into numbers they can be consumed by popular machine learning models. Pro tip : always check the dimension, sequence (order of inputs), and type of inputs the model architecture is expecting. These numbers don’t lie and they can give you a hint to how to fit something complex together. Side note: encoding is not to be confused with auto encoder a model architecture.
Our algorithm is numeric but the input data won’t always be.
Converting text, categorical and other complex data into numeric values is a true challenge. And continues to be a research area.
Categorical encoder / categorical data encoder
One hot encoding
Prefer having the code to try this out? Paid subscribers request your code here. hi@uniqtech.co
The output dimension of one hot encoder is row number - the number of data samples, column number - the number of unique values. In natural language processing (NLP), bag of words, it can be the number of unique words, often called the vocabulary.
One hot encoding assumes each of the label is independent from each other. For example, a sample cannot be both cat and dogs. A familiar example is that a coin is either head or tail (in none quantum computing world). It has to be either a cat or dog. There is no overlap of categories. It result in a sparse matrix, each row should have all entries as 0, except for the one corresponding, correct column label as 1. For example, if cat is the zeroth position [1,0,0, 0…..] there are are as many zeroes as there are unique values to encode. In the cat, dog, bird, horse example, the encoding for cat is [1,0,0,0], for dog is [0,1,0,0]. The dot product of two rows of different labels will always be zero. The dot product of two rows of the same label will always be 1.
"one hot encoding each row should only have 1 label while the others are 0"
Encoding data using one hot encoding can turn the original one column into many new columns, hence can take up space, time, cost and increasing search space, computing time, requiring more training data.
See paid subscriber only blog for One Hot Encoding in Pandas and an example of CountVectorizer which is a related concept in Natural Language Processing (NLP). Link here. Note you must accept the blogger invite to access the private blog.

It’s also important to use the above link to understand the difference between ordinal versus non-ordinal data. Basically one hot encoding is used for non-ordinal data.

Previously handling missing data and imputation strategy visuals also appear in the paid subscriber only blog. Link here.
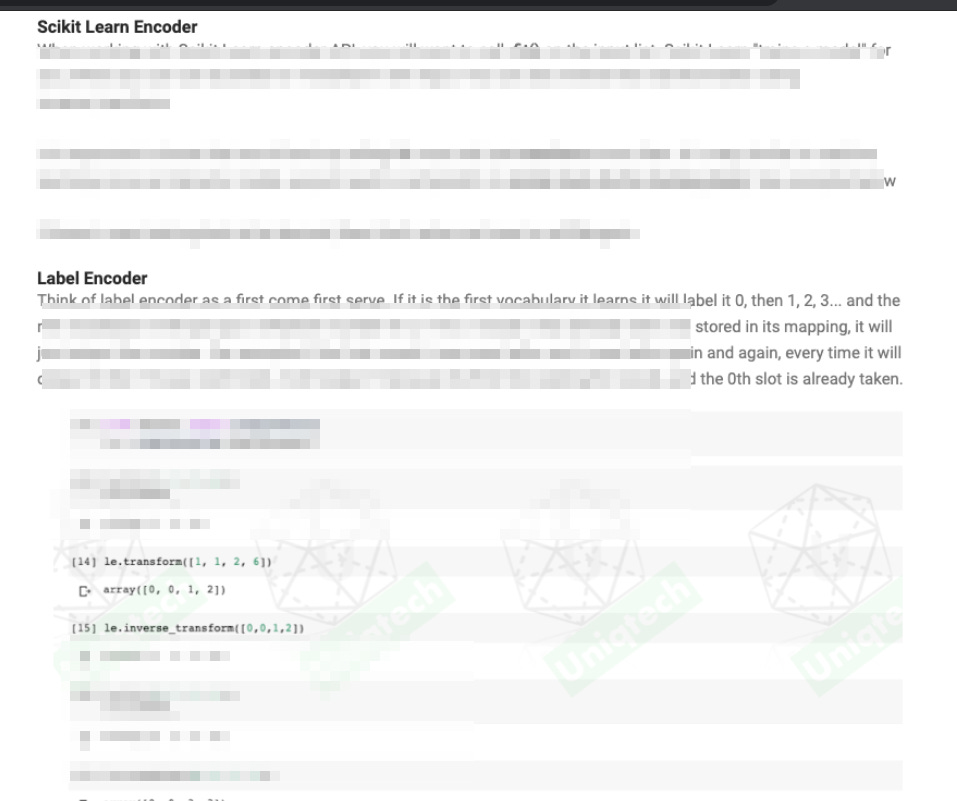
ScikitLearn LabelEncoder
Prefer having the code to try this out? Paid subscribers request your code here. hi@uniqtech.co
Label encoder is a very simple encoder. It is much easier to understand than one hot encoding. It is also for categorical data. But it works better for ordinal data, or a pre-sorted input list, because its output imply that the labels are not strictly independent. Read more here, on the private blog. This can be confusing. We plan to have youtube videos to accompany these articles soon. Let us know if you want it sooner hi@uniqtech.co
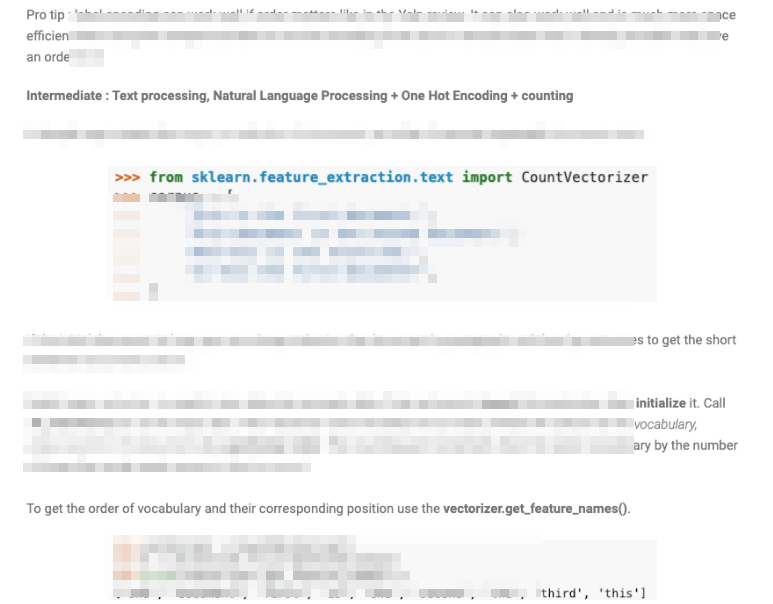
Encoding Texts
In the private blog, we explain that one hot encoding can be used to encode texts. That is a basic yet useful technique. Modern day techniques are more advanced. It is called word embedding. Happy to explain more in the near future.
To understand more about embedding you can read our intro blurb on medium. Paid subscribers request free link here hi@uniqtech.co
Encoding Images
Turning images into tensors really warrants its own post so that will be explained in the near future as well. We will also cover scaling images, normalizing. To get a taste of encoding images as tensors read our intro to tensor post on Medium. Paid subscribers can request a copy for free. Understanding Tensors and Matrices.
Note on paid subscribers:
Paid subscribers get access to all our Medium and blog posts for the time of active paid subscriptions. Each paid period is one month. Private blog invitation is sent when the first payment is confirmed.
Scaling, Standardizing, Normalization
An important topic in the near future is scaling, which makes training data more stable, easier to compute, and easier to store. That’s why you see scikit learn utilities such as StandardScaler.