
End-to-End Machine Learning Course - Machine Learning 101 Part 2 - Machine Learning Workflow
End-to-End Machine Learning Course - Machine Learning 101 Part 2 - Machine Learning Workflow
This article is for paid subscribers only. Please subscribe.
We send this course to your inbox as it is developed. You will get important machine learning resources in your inbox. Example: recently we sent out a limited data only free Pytorch programming book that we found on the internet! 141 pages!
A great analogy for machine learning models and architecture is they are like babies, ready to learn, but do not know anything. Through experiencing, trial and error, being taught (all part of training), babies gradually learn what right or wrong. What to do and what not to do.
As previously mentioned in End-to-End Machine Learning Course Part 1: machine learning algorithms are like babies, they learn from examples, a lot of examples in forms of data. The first step is always to gather or find readily available datasets.
MNIST is a solved dataset where you can classify 28x28 pixel images of handwritten digits from 0 to 9. It is easy to get high accuracy. A more sophisticated modern alternative is Fashion MNIST, a dataset of retail clothing items such as shirts and pants, to be classified. It is non-trivial. You can also find free datasets on data science competition site called Kaggle, acquired by Google. University of California Irvine (UCI) free machine learning dataset site.
What happens then is illustrated in these infographics below. We created them specified for our subscribers. All rights reserved. They can only be used by Uniqtech on our own sites.
This is a a machine learning workflow chart we illustrated specifically for this course.
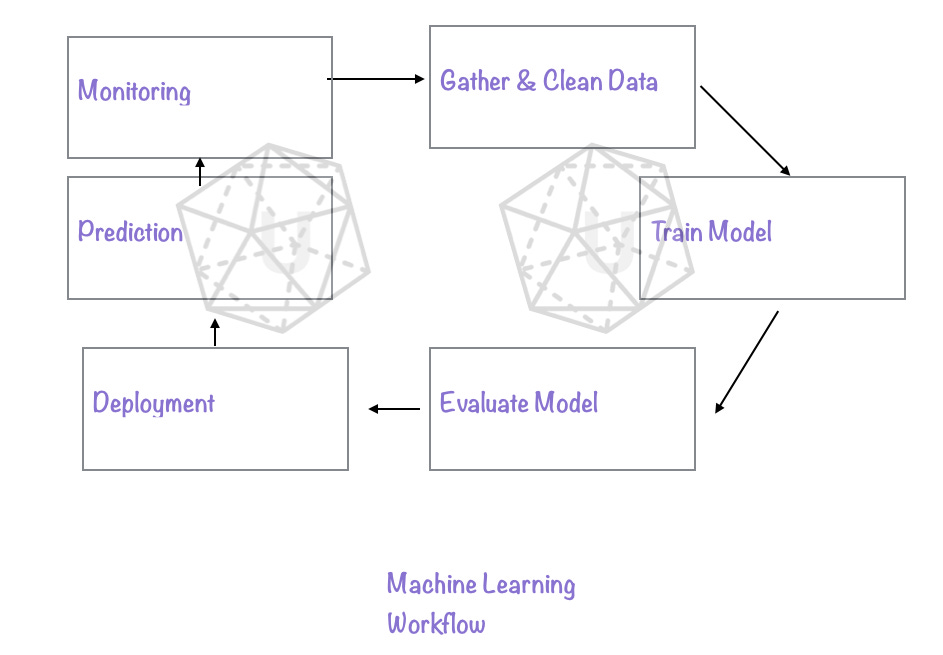
And we will try to refer back to it often. For example the GPU accelerated computing usage is especially useful in training model phase.
Announcement insert: The third part of exploratory data analysis, the most important part, and the easter eggs (high quality content of the month) will be sent to paid subscribers within the next two days. If you haven’t, subscribe today. Easter eggs are not published on substack.com
This workflow starts with a bulky, important and lengthy gather and clean data phase. Then the model is trained with train data, and evaluated on test data, eventually it is also used once against validation data, which mimics unseen real world data. Then it is deployed to production (optional) and its performance is monitored. Such as in the case of Uber and Lyft pricing models.
Sometimes a machine learning model never gets deployed and that’s okay. May be the inference or prediction phase is a batch job, which happens not so frequently.
It is possible that gather & clean data takes a lot of effort and expertise.
It is common to repeat the clean, train and evaluate steps as many times as needed. This is a small loop of feedback that often circles quite a few times before reaching satisfaction.
In the case of using an existing, well trained model from a given repository of models, known as model zoo, it is possible to deploy right away. For example, Intel OpenVino Edge computing for machine learning and deep learning offers model zoo of models in intermediate representations (IR) ready for deployment, which requires trained models to be converted to IR and in this case it is already the right format.
Thanks for reading. Please check back on uniqtech.substack.com for updates to this article. Your inbox copy cannot be updated. Please note our content is for personal and non-commercial use only. It is for enriching your knowledge and not meant for production nor commercial usage. Please read our disclaimer here.